更改命名空間的做法網路上很多教學
這篇記錄更改命名空間後編譯不過的問題
改變命名空間後
要在solution點右鍵選property
設定debug地方只勾選要編譯成DLL的專案
才會編譯成功
2013年12月20日 星期五
2013年10月30日 星期三
C# 序列化 反序列化binaryformatter
序列化目前就筆者所知有三種
一種序列化為binary型式
一種序列化為xml型式
另一種序列化為json型式
其中json型式沒有支援輸出檔案,要自己做
本篇用binaryformat序列化法
[Serializable]
class MessageEvent: ISerializable
{
public MessageEvent(SerializationInfo info, StreamingContext context) {
message= (string)info.GetValue("message", typeof(string));
timestamp = (long)info.GetValue("timestamp", typeof(long));//typeof型態要符合變數型態,否則會報TargetInvocationException
property = (string)info.GetValue("property", typeof(string));
}
public void GetObjectData(SerializationInfo info, StreamingContext context)
{
info.AddValue("label",variable);
info.AddValue("label",variable);
info.AddValue("label",variable);
}
}
序列化:
MessageEvent mesEvent= new MessageEvent("hello earth",100L,"new");
string FILE_DIRECTORY = "D:\\SerializeFile\\";
DateTime saveNow = DateTime.Now;
String fileTimestamp = saveNow.ToString(("yyyyMMddHHmmssfff"));
BinaryFormatter serializer = new BinaryFormatter();
FileStream file = new FileStream(FILE_DIRECTORY+fileTimestamp+".txt", FileMode.Create);
serializer.Serialize(file, mesEvent);
file.Close();
public static void DeserializeFile() {
while (true)
{
string[] filesnames = Directory.GetFiles(FILE_DIRECTORY);
foreach (string filename in filesnames)
{
if(File.Exists(filename)){
MessageEvent resultMesEvent = null;
FileStream file = null;
try
{
BinaryFormatter serializer = new BinaryFormatter();
file = new FileStream(filename,FileMode.Open);
resultMesEvent = (MessageEvent)serializer.Deserialize(file);
Console.WriteLine("Serialize Success");
}
catch (TargetInvocationException ex) {
Console.WriteLine("please check serialized obj construct");
}
catch (System.IO.IOException ioe)
{
Console.WriteLine(ioe);
}
finally {
file.Close();
File.Delete(filename);//file.Close之後才delete
}
}
}
}
}
一種序列化為binary型式
一種序列化為xml型式
另一種序列化為json型式
其中json型式沒有支援輸出檔案,要自己做
本篇用binaryformat序列化法
[Serializable]
class MessageEvent: ISerializable
{
public MessageEvent(SerializationInfo info, StreamingContext context) {
message= (string)info.GetValue("message", typeof(string));
timestamp = (long)info.GetValue("timestamp", typeof(long));//typeof型態要符合變數型態,否則會報TargetInvocationException
property = (string)info.GetValue("property", typeof(string));
}
public void GetObjectData(SerializationInfo info, StreamingContext context)
{
info.AddValue("label",variable);
info.AddValue("label",variable);
info.AddValue("label",variable);
}
}
序列化:
MessageEvent mesEvent= new MessageEvent("hello earth",100L,"new");
string FILE_DIRECTORY = "D:\\SerializeFile\\";
DateTime saveNow = DateTime.Now;
String fileTimestamp = saveNow.ToString(("yyyyMMddHHmmssfff"));
BinaryFormatter serializer = new BinaryFormatter();
FileStream file = new FileStream(FILE_DIRECTORY+fileTimestamp+".txt", FileMode.Create);
serializer.Serialize(file, mesEvent);
file.Close();
反序列化:
public static void DeserializeFile() {
while (true)
{
string[] filesnames = Directory.GetFiles(FILE_DIRECTORY);
foreach (string filename in filesnames)
{
if(File.Exists(filename)){
MessageEvent resultMesEvent = null;
FileStream file = null;
try
{
BinaryFormatter serializer = new BinaryFormatter();
file = new FileStream(filename,FileMode.Open);
resultMesEvent = (MessageEvent)serializer.Deserialize(file);
Console.WriteLine("Serialize Success");
}
catch (TargetInvocationException ex) {
Console.WriteLine("please check serialized obj construct");
}
catch (System.IO.IOException ioe)
{
Console.WriteLine(ioe);
}
finally {
file.Close();
File.Delete(filename);//file.Close之後才delete
}
}
}
}
}
C# 列印日期(顯示毫秒)
DateTime saveNow = DateTime.Now;
System.Console.WriteLine("step 1: " + saveNow.ToString("yyyy/MM/dd tt hh:mm:ss.fffff"));
String str = saveNow.ToString(("yyyyMMddHHmmssfff"));
System.Console.WriteLine("step 1: " + saveNow.ToString("yyyy/MM/dd tt hh:mm:ss.fffff"));
String str = saveNow.ToString(("yyyyMMddHHmmssfff"));
2013年10月24日 星期四
C# log4net用法
http://luckystar1216.pixnet.net/blog/post/13159723-%E4%BD%BF%E7%94%A8log4net%E7%B4%80%E9%8C%84%E7%A8%8B%E5%BC%8F%E5%9F%B7%E8%A1%8C%E9%81%8E%E7%A8%8B%E7%9A%84log(for-c%23)
log4net需要靠.xml配置來指定Log格式
log要寫入的路徑
別人已經寫得很詳盡
貼個網址讓自己方便查閱
log4net需要靠.xml配置來指定Log格式
log要寫入的路徑
別人已經寫得很詳盡
貼個網址讓自己方便查閱
2013年10月14日 星期一
Run Flume with Eclipse on Windows
本文是在windows用eclipse啟動flume agent
1.
首先去官方網站下載
flume原始碼,我下載的是flume 1.4版
以existing maven project之姿,匯入eclipse
2.
找到flume-parent
maven編譯之,參數設定如下




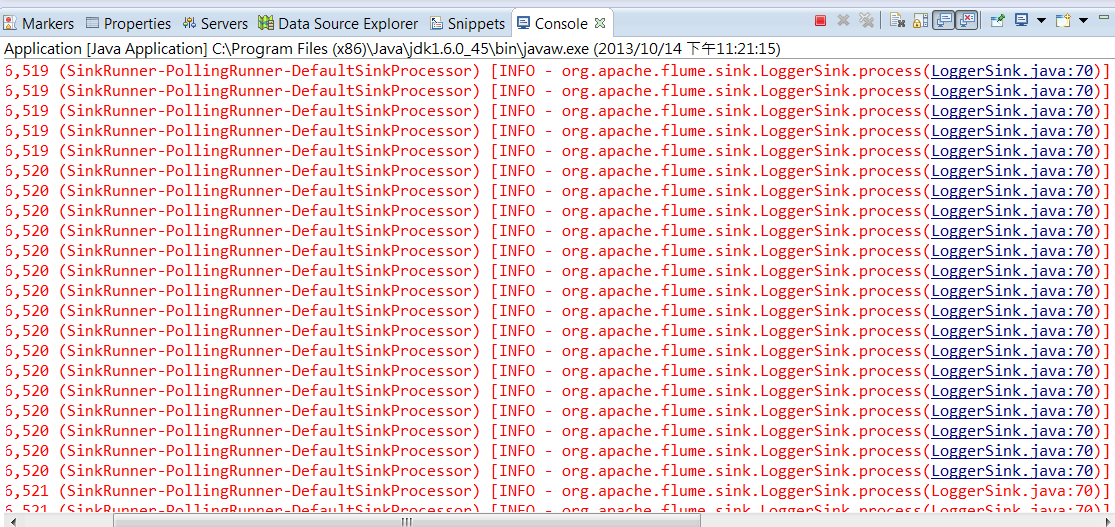
6.接著會看到console一直跑下面結果,啟動成功
mvn package -DskipTests -Drat.numUnapprovedLicenses=100
1.
首先去官方網站下載
flume原始碼,我下載的是flume 1.4版
以existing maven project之姿,匯入eclipse
2.
找到flume-parent
maven編譯之,參數設定如下
4.
修改log4j.properties的設定
flume.root.logger=DEBUG,console
#flume.root.logger=INFO,LOGFILE
5.
找到flume-ng-node的Application.java
run as java application
參數設定如下
6.接著會看到console一直跑下面結果,啟動成功
mvn package -DskipTests -Drat.numUnapprovedLicenses=100
2013年10月7日 星期一
Clinet端寫入Buffer
每個put操作都是遠端程序呼叫(Remote procedure call,RPC),將資料從client端傳輸至server並返回。
如果資料傳輸速度1ms那麼表示每秒可以處理1000次往返。
採用buffer方式傳送資料可以減少電腦執行RPC
Hbase Client端預設不使用緩衝區(buffer),
啟用buffer方法如下:
table.setAutoFlush(false);
將autoflush設定為false
如此一來可以將資料寫入client端的buffer
如果要強迫將資料寫入hbase時,呼叫
void flushCommits() throws IOException
刷新buffer兩種方式:
1.Explict flush(明確刷新):
直接在程式中呼叫flushCommets()
2.Implict flush(隱含刷新)
當呼叫put()或者setWriteBufferSize()會觸發flushCommits()
HTable的close() method也會觸發刷新
Configuration conf = HBaseConfiguration.create();
HBaseHelper help = HBaseHelper.getHelper(conf);
help.dropTable("usertable");
help.createTable("usertable", "cf1","cf2","cf3");
HTable table = new HTable(conf,"usertable");
System.out.println("Auto Flush:"+table.isAutoFlush());
table.setAutoFlush(false);
KeyValue kv = new KeyValue(Bytes.toBytes("RK1"),Bytes.toBytes("cf1"),Bytes.toBytes("qual"),Bytes.toBytes("value"));
Put put1 = new Put(Bytes.toBytes("RK1"));
put1.add(kv);
table.put(put1);
Put put2 =new Put(Bytes.toBytes("RK2"));
put2.add(Bytes.toBytes("cf1"),Bytes.toBytes("quali1"),Bytes.toBytes("val2"));
table.put(put2);
Get get =new Get(Bytes.toBytes("RK1"));
Result result = table.get(get);
System.out.println("FirstResult"+result);
table.flushCommits();
Result res2 =table.get(get);
System.out.println(res2);
table.close();
注意客戶端程式不可以中途中斷
否則緩衝區的資料可不會自己跑去Hbase
如果資料傳輸速度1ms那麼表示每秒可以處理1000次往返。
採用buffer方式傳送資料可以減少電腦執行RPC
Hbase Client端預設不使用緩衝區(buffer),
啟用buffer方法如下:
table.setAutoFlush(false);
將autoflush設定為false
如此一來可以將資料寫入client端的buffer
如果要強迫將資料寫入hbase時,呼叫
void flushCommits() throws IOException
刷新buffer兩種方式:
1.Explict flush(明確刷新):
直接在程式中呼叫flushCommets()
2.Implict flush(隱含刷新)
當呼叫put()或者setWriteBufferSize()會觸發flushCommits()
HTable的close() method也會觸發刷新
Configuration conf = HBaseConfiguration.create();
HBaseHelper help = HBaseHelper.getHelper(conf);
help.dropTable("usertable");
help.createTable("usertable", "cf1","cf2","cf3");
HTable table = new HTable(conf,"usertable");
System.out.println("Auto Flush:"+table.isAutoFlush());
table.setAutoFlush(false);
KeyValue kv = new KeyValue(Bytes.toBytes("RK1"),Bytes.toBytes("cf1"),Bytes.toBytes("qual"),Bytes.toBytes("value"));
Put put1 = new Put(Bytes.toBytes("RK1"));
put1.add(kv);
table.put(put1);
Put put2 =new Put(Bytes.toBytes("RK2"));
put2.add(Bytes.toBytes("cf1"),Bytes.toBytes("quali1"),Bytes.toBytes("val2"));
table.put(put2);
Get get =new Get(Bytes.toBytes("RK1"));
Result result = table.get(get);
System.out.println("FirstResult"+result);
table.flushCommits();
Result res2 =table.get(get);
System.out.println(res2);
table.close();
注意客戶端程式不可以中途中斷
否則緩衝區的資料可不會自己跑去Hbase
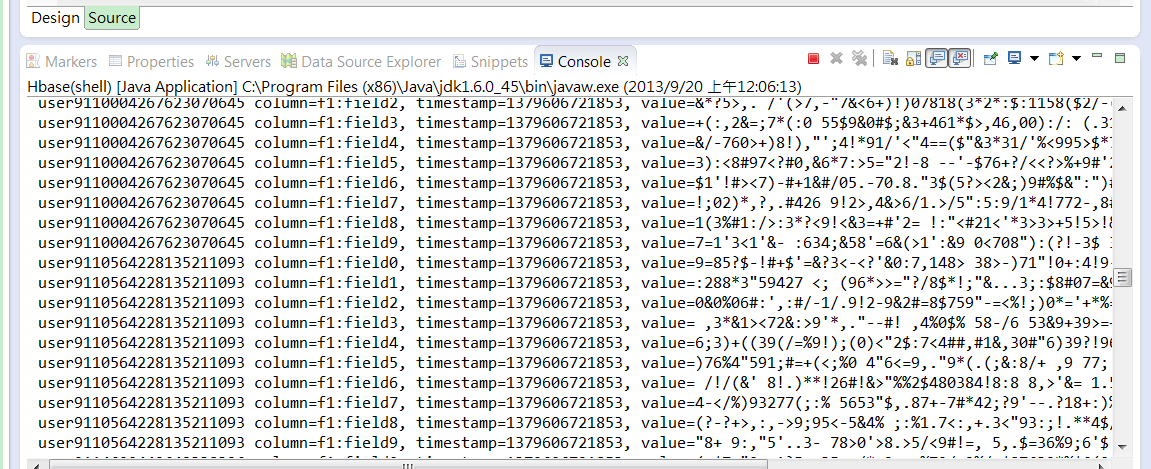
hbase program雜記&KeyValue類別
Configuration conf =HBaseConfiguration.create();
這行程式碼背後運作是使用當前java類別路徑,加載hbase-default.xml,hbase-site.xml組態檔。
HBase可以對每個columnfamily儲存多個版本,每個版本用timestamp,並用降冪順序來儲存他們。timestamp型態是long,單位是毫秒,紀錄的時間是從1970年1月1日開始到今天的時間。
所以必須確保server擁有正確的時間且彼此是同步的
當有資料匯入Hbase,若不在Client端指定時間,則會以server時間為準。
例子:
先匯入rowkey為rk1, columnfamily1為cf1的一筆資料
put 'usertable','rk1','cf1','vlaue1'
0 row(s) in 0.2300 seconds
再匯入同樣columnfamily與rowkey的資料,value不一樣
put 'usertable','rk1','cf1','ddddd'
0 row(s) in 0.0100 seconds
ROW COLUMN+CELL
rk1 column=cf1:, timestamp=1381154563122, value=ddddd
1 row(s) in 0.0260 seconds
指定列出版本數就會列出過去曾經匯入的紀錄
scan 'usertable',{VERSIONS => 3}
ROW COLUMN+CELL
rk1 column=cf1:, timestamp=1381154563122, value=ddddd
rk1 column=cf1:, timestamp=1381154533794, value=vlaue1
1 row(s) in 0.0220 seconds
scan 'usertable',{VERSIONS => 2}
ROW COLUMN+CELL
rk1 column=cf1:, timestamp=1381154563122, value=ddddd
rk1 column=cf1:, timestamp=1381154533794, value=vlaue1
1 row(s) in 0.0230 seconds
KeyValue類別是很重要的API
Hbase Client很常用
用來包裝"資料"以及"特定儲存單元的位置",位置可以是rowkey,column family名稱,column qualifier以及timestamp,KeyValue提供大量constructor供各位使用。長相大致這樣:KeyValue(byte[] row,int offset,int rowlength);
在Hbase0.97板之後KeyValue改名為Cell
KeyValue提供大量implement Comparator的內部class。
KeyValue裡面的method可以用來比較部分已儲存的資料以及確定其類型....and so on.
這行程式碼背後運作是使用當前java類別路徑,加載hbase-default.xml,hbase-site.xml組態檔。
HBase可以對每個columnfamily儲存多個版本,每個版本用timestamp,並用降冪順序來儲存他們。timestamp型態是long,單位是毫秒,紀錄的時間是從1970年1月1日開始到今天的時間。
所以必須確保server擁有正確的時間且彼此是同步的
當有資料匯入Hbase,若不在Client端指定時間,則會以server時間為準。
例子:
先匯入rowkey為rk1, columnfamily1為cf1的一筆資料
put 'usertable','rk1','cf1','vlaue1'
0 row(s) in 0.2300 seconds
再匯入同樣columnfamily與rowkey的資料,value不一樣
put 'usertable','rk1','cf1','ddddd'
0 row(s) in 0.0100 seconds
打上scan table只會列出最新版本的資料
scan 'usertable'ROW COLUMN+CELL
rk1 column=cf1:, timestamp=1381154563122, value=ddddd
1 row(s) in 0.0260 seconds
指定列出版本數就會列出過去曾經匯入的紀錄
scan 'usertable',{VERSIONS => 3}
ROW COLUMN+CELL
rk1 column=cf1:, timestamp=1381154563122, value=ddddd
rk1 column=cf1:, timestamp=1381154533794, value=vlaue1
1 row(s) in 0.0220 seconds
scan 'usertable',{VERSIONS => 2}
ROW COLUMN+CELL
rk1 column=cf1:, timestamp=1381154563122, value=ddddd
rk1 column=cf1:, timestamp=1381154533794, value=vlaue1
1 row(s) in 0.0230 seconds
KeyValue類別是很重要的API
Hbase Client很常用
用來包裝"資料"以及"特定儲存單元的位置",位置可以是rowkey,column family名稱,column qualifier以及timestamp,KeyValue提供大量constructor供各位使用。長相大致這樣:KeyValue(byte[] row,int offset,int rowlength);
在Hbase0.97板之後KeyValue改名為Cell
KeyValue提供大量implement Comparator的內部class。
KeyValue裡面的method可以用來比較部分已儲存的資料以及確定其類型....and so on.
2013年10月4日 星期五
在windows上跑Hbase書上範例程式
本文適合想在(或只能在)windows上練習hbase程式的觀眾
"HBase技術手冊"這本書程式都是零散的片段,
不親自跑他的程式還真不知道作者在講什麼
那種感覺就像看一本沒有圖片、沒有地圖的旅遊書籍
裡面詳細介紹紫禁城
看完書之後立刻把你丟到紫禁城的太和殿
城內沒有路標情況下,你仍然不會知道怎樣走到乾清宮
步驟:
1.參考下面連結文章在windows裝上Hbase0.94.4
(別裝0.97因為API跟書上的有出入)
裝完之後打開run hbase起來
2. check out Hbase範例程式,匯入eclipse有裝hbase的workspace
https://github.com/larsgeorge/hbase-book
3.將範例程式碼package複製貼上到src/main/java底下去跑就可以了
PutExample.java這個範例跑完
可以打開hbase shell
下指令查看是否有建立table以及table已經有存放row了
"HBase技術手冊"這本書程式都是零散的片段,
不親自跑他的程式還真不知道作者在講什麼
那種感覺就像看一本沒有圖片、沒有地圖的旅遊書籍
裡面詳細介紹紫禁城
看完書之後立刻把你丟到紫禁城的太和殿
城內沒有路標情況下,你仍然不會知道怎樣走到乾清宮
步驟:
1.參考下面連結文章在windows裝上Hbase0.94.4
(別裝0.97因為API跟書上的有出入)
"windows 7+hbase (0.97)+eclipse (Juno) 在windows 7上用Eclipse跑hbase"
http://yehyenping.blogspot.tw/2013/09/windowshbaseeclipse.html裝完之後打開run hbase起來
2. check out Hbase範例程式,匯入eclipse有裝hbase的workspace
https://github.com/larsgeorge/hbase-book
3.將範例程式碼package複製貼上到src/main/java底下去跑就可以了
PutExample.java這個範例跑完
可以打開hbase shell
下指令查看是否有建立table以及table已經有存放row了
2013年9月25日 星期三
1.PNG)
2.PNG)
3.PNG)
4.PNG)
2013年9月19日 星期四
Run YCSB on Windows7 with Eclipse 在windows 7 上跑YCSB
終於讓筆者給弄出來了
這樣不用linux也能在windows上跑hbase、YCSB啦
(各位如果能在linux上裝eclipse跑就在linux上面跑吧,因為hbase跟YCSB原本就是要在linux上跑的嘛!!!!)
這篇文章所說的YCSB以及HBase都在Windows上運作,只用Eclipse這個工具啟動他們。
因為YCSB原本是用來測試Hbase0.94.4,筆者另外在自己windows電腦安裝hbase0.94.4,安裝方法其實跟筆者之前安裝hbase0.97差不多。
這樣可以當練習專用的hbase。
其實Hbase0.96之後的API有大幅更動,所以想翻閱聖經本對照source code學習hbase會有困難度,因為課本裡面很多API在Hbase0.96已經消失了........= =
那麼咱正式進入安裝的步驟吧!!!!!
=================================================================
前提:用Eclipse啟動Hbase0.94.4,並建立名稱為usertable的表格,這個表格有三個columnfamily。
(You must run Hbase0.94.4 with Eclipse on Windows,and create a table named 'usertable'.
create 'usertabble','f1',f2','f3'
(不一定要三個columnfamily)
1. 用SVN check out YCSB 0.1.4
2. Import Existing Maven Project,匯入完畢專案架構如下圖,root是所有專案的根目錄。將root專案編譯表示也將其他專案編譯的意思。

3.設定環境變數(configurate variable)
a.將hbase-site.xml換成你正在使用的hbase裡面的hbase-site.xml檔案
我使用的是hbase0.94.4,而且都在hbase-default.xml設定參數,所以我將hbase-default.xml複製到YCSB的hbase-binding的conf之下,然後將檔案改名為hbase-site.xml。

b.在hbase-binding的pom.xml設定採用的hbase與hadoop版本
筆者採用hbase 0.94.4版 hadoop 1.0.4版

c. 設定root目錄之下的pom.xml ,如圖所示。
設定這邊是為了統一hbase-bind專案底下的jar包都採用slf4j-api-1.6.4、slf4j-log4j12-1.6.4。不這樣做的話會出現錯誤訊息告知你的slf4j的jar包太舊。

4.編譯專案,我這次在cmd編譯的,eclipse沒試過。
mvn package -DskipTests
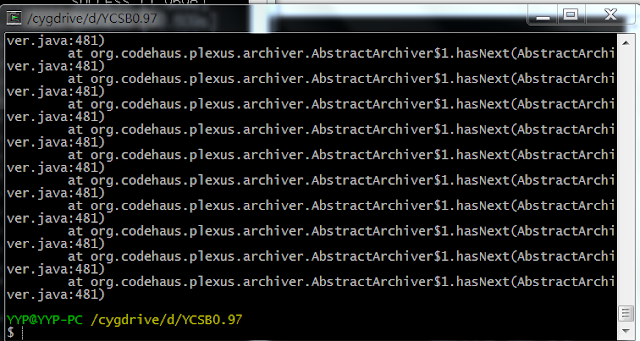
如果編譯出現如下問題
at
org.codehaus.plexus.archiver.AbstractArchiver$1.hasNext(AbstractArchiver.java
從網路聽說mvn.bat檔案之中加上以下這行
set MAVEN_OPTS=-Xmx512m -Xms128m -Xss10m
改變JVM的記憶體配置會過。筆者也過了
上圖是cygwin的錯誤結果,筆者未設定JVM記憶體配置之前在cmd也曾發生同樣錯誤,
這個錯誤訊息在app4u是說:
"This is due to different incompatible versions of a library. The jar file that contains org.codehaus.plexus.archiver.AbstractArchiver$1.hasNext()Z is not present on your classpath. However there is a different version of the same jar on the classpath."
網站如下:
http://solutions.apps4u.co/en/class/org.codehaus.plexus.archiver.AbstractArchiver$1/method/hasNext/()Z/error/java.lang.NoSuchMethodException/
我依照這網址的方法照做,但是問題依然存在。
5.執行YCSB
a.如圖所示

b.這邊workloads是相關參數設定檔案,其他jar包必須加入classpath,如圖所示,否則YCSB會抗議。

<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.6.4</version>
</dependency>
<dependency>
<!-- 以下是我自己加上 -->
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.4</version>
</dependency>
要確認slf4j版本有沒有正確配置,請各位看倌打開root目錄下的pom.xml 選擇Dependency Hierachy,在右上角搜尋slf,請對照圖中使用的slf4j-api以及slf4j-log4j12的版本
所有的jar檔案採用的slf4j的jar檔案必須都採用同樣版本編譯。

c.Arguments設定:
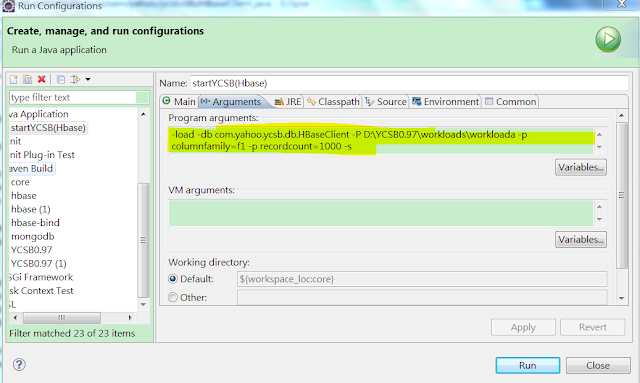
6.大功告成


參考網站:
http://cloudfront.blogspot.tw/2013/02/how-to-benchmark-hbase-using-ycsb.html#.UjhVwsZHIZ4
(PS:網站掛點小密技或者有些網站在某些地方會被擋住,各位可以將網址貼到wayback machine搜尋,如此一來就可以搭時光機回去看網站內容)
這樣不用linux也能在windows上跑hbase、YCSB啦
(各位如果能在linux上裝eclipse跑就在linux上面跑吧,因為hbase跟YCSB原本就是要在linux上跑的嘛!!!!)
因為YCSB原本是用來測試Hbase0.94.4,筆者另外在自己windows電腦安裝hbase0.94.4,安裝方法其實跟筆者之前安裝hbase0.97差不多。
這樣可以當練習專用的hbase。
其實Hbase0.96之後的API有大幅更動,所以想翻閱聖經本對照source code學習hbase會有困難度,因為課本裡面很多API在Hbase0.96已經消失了........= =
那麼咱正式進入安裝的步驟吧!!!!!
=================================================================
前提:用Eclipse啟動Hbase0.94.4,並建立名稱為usertable的表格,這個表格有三個columnfamily。
(You must run Hbase0.94.4 with Eclipse on Windows,and create a table named 'usertable'.
create 'usertabble','f1',f2','f3'
(不一定要三個columnfamily)
1. 用SVN check out YCSB 0.1.4
2. Import Existing Maven Project,匯入完畢專案架構如下圖,root是所有專案的根目錄。將root專案編譯表示也將其他專案編譯的意思。

3.設定環境變數(configurate variable)
a.將hbase-site.xml換成你正在使用的hbase裡面的hbase-site.xml檔案
我使用的是hbase0.94.4,而且都在hbase-default.xml設定參數,所以我將hbase-default.xml複製到YCSB的hbase-binding的conf之下,然後將檔案改名為hbase-site.xml。
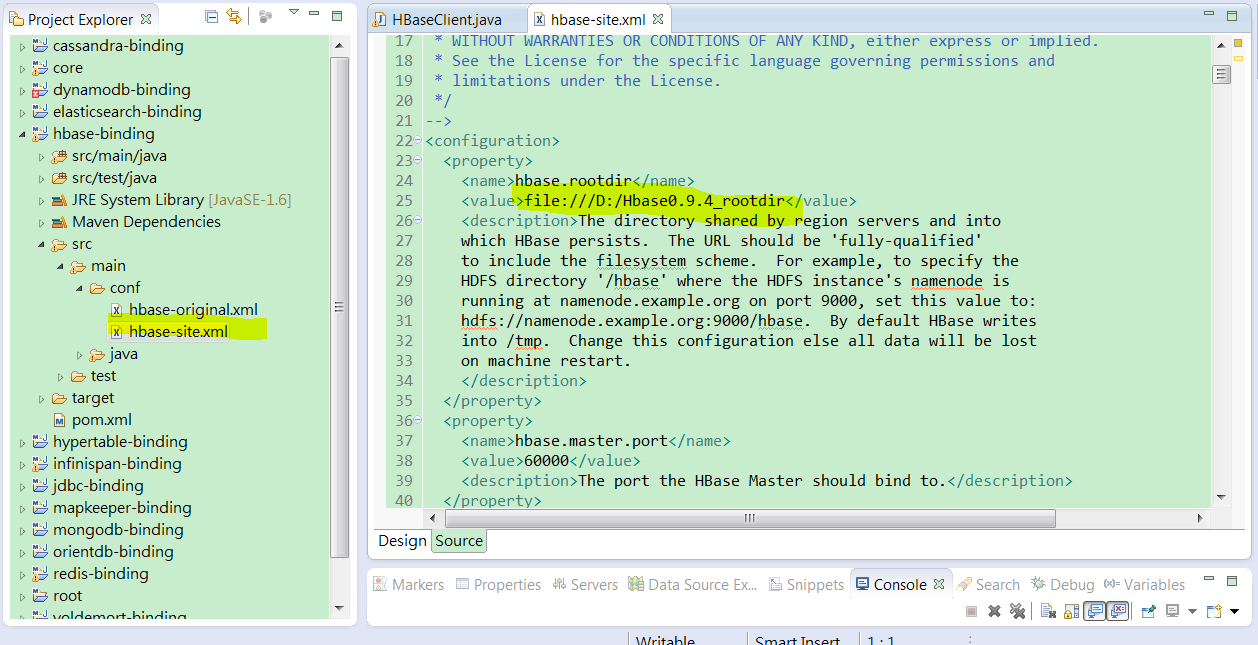
b.在hbase-binding的pom.xml設定採用的hbase與hadoop版本
筆者採用hbase 0.94.4版 hadoop 1.0.4版

c. 設定root目錄之下的pom.xml ,如圖所示。
設定這邊是為了統一hbase-bind專案底下的jar包都採用slf4j-api-1.6.4、slf4j-log4j12-1.6.4。不這樣做的話會出現錯誤訊息告知你的slf4j的jar包太舊。

4.編譯專案,我這次在cmd編譯的,eclipse沒試過。
mvn package -DskipTests
如果編譯出現如下問題
at
org.codehaus.plexus.archiver.AbstractArchiver$1.hasNext(AbstractArchiver.java

從網路聽說mvn.bat檔案之中加上以下這行
set MAVEN_OPTS=-Xmx512m -Xms128m -Xss10m
改變JVM的記憶體配置會過。筆者也過了
上圖是cygwin的錯誤結果,筆者未設定JVM記憶體配置之前在cmd也曾發生同樣錯誤,
這個錯誤訊息在app4u是說:
"This is due to different incompatible versions of a library. The jar file that contains org.codehaus.plexus.archiver.AbstractArchiver$1.hasNext()Z is not present on your classpath. However there is a different version of the same jar on the classpath."
網站如下:
http://solutions.apps4u.co/en/class/org.codehaus.plexus.archiver.AbstractArchiver$1/method/hasNext/()Z/error/java.lang.NoSuchMethodException/
我依照這網址的方法照做,但是問題依然存在。
5.執行YCSB
a.如圖所示

b.這邊workloads是相關參數設定檔案,其他jar包必須加入classpath,如圖所示,否則YCSB會抗議。

上圖是筆者原本安裝的classpath配置。
其實jar檔案只留下hbase-binding跟hadoop-core即可(感謝120的留言提醒),但是記得要在root的pom.xml加上這麼一段。
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.6.4</version>
</dependency>
<dependency>
<!-- 以下是我自己加上 -->
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.4</version>
</dependency>
要確認slf4j版本有沒有正確配置,請各位看倌打開root目錄下的pom.xml 選擇Dependency Hierachy,在右上角搜尋slf,請對照圖中使用的slf4j-api以及slf4j-log4j12的版本
所有的jar檔案採用的slf4j的jar檔案必須都採用同樣版本編譯。

c.Arguments設定:

6.大功告成

參考網站:
http://cloudfront.blogspot.tw/2013/02/how-to-benchmark-hbase-using-ycsb.html#.UjhVwsZHIZ4
(PS:網站掛點小密技或者有些網站在某些地方會被擋住,各位可以將網址貼到wayback machine搜尋,如此一來就可以搭時光機回去看網站內容)
2013年9月10日 星期二
maven build錯誤解決辦法
1.如果在執行hbase或者執行maven,遇到與jar檔案有關的bug時候,那麼就重新build一次,要build之前可以去.m2/repository/org下所對應的資料夾砍掉再重新build一次。
例如:
出現jruby-complete-1.6.8.jar檔案的bug
那麼就去
C:\OOXXX\.m2\repository\org\jruby\jruby-complete
將1.6.8資料夾刪掉之後再重新build
2.如果在eclipse或者cmd上maven build錯誤,可以嘗試著在cygwin之下做maven build。
===============================================================


2013年9月7日 星期六
windows 7+hbase (0.97)+eclipse (Juno) 在windows 7上用Eclipse跑hbase
壹、所需系統環境配置與軟體
一、JDK1.6
二、Eclipse(Kepler或Juno皆可])
三、安裝maven3.05以及eclipse套件也要plugin maven
(安裝辦法請參考其他網友的blog)
四、安裝JRuby(事後證明不必安裝)
據說是為了下hbase shell指令,因為hbase shell是採用JRuby執行
(但是筆者自己安裝時候沒下載JRuby依然可以用eclipse啟動hbase shell,大概是因為我用maven build時maven已經幫忙下載JRuby的jar檔案了,如下圖)
五、安裝cygwin並且設定環境變數
(安裝方式請參考其他網站,官網有安裝檔案可以一鍵next按到底)
據網友表示這是為了能夠下達start指令啟動hbase
若在eclipse或者命令提示字元maven build有錯時,可以嘗試在cygwin底下build程式。
去pom.xml所在目錄下達指令:mvn clean install -DskipTests
筆者在某些場合windows無法編譯過,所以只好用cygwin編譯了
貳、安裝篇
一、安裝Hbase
1.用svn抓hbase原始碼
位址如下 (位址可能會有變化,請留意)
http://svn.apache.org/repos/asf/hbase/trunk

2. Import "Existing Maven Project"
a.選擇Hbase source code根目錄,全部打鉤匯入,否則import檔案不全會有錯誤。

b.如果是第一次安裝Maven,在Import時可能會多一個build-helper-maven-plugin,那麼按下一步

c.安裝maven plugin的畫面

d.開始安裝maven plugin,筆者第一次安裝約莫等了十幾分鐘

e.裝完之後的專案架構如下圖。
( i ). hbase專案是根目錄,裡面已經放一堆.sh檔案、ruby檔案(.rb)、設定hbase-site.xml、regionservers。
(ii) 因為筆者Import進來之後,maven已經自動幫我將source code加進來。所以就不執行Maven generate-sources。如果讀者Import之後裡面沒有src/main/java、src/test/java,也就是沒有.java檔案的話或者懷疑.m2/reposity目錄下少了某些jar檔案,就執行Maven generate-sources,之後執行maven build

3.設定環境變數(設定參數)
( i ). 設定hbase-default.xml
(或者hbase-site.xml,在hbase-site.xml添加參數的話會改寫(override)hbase-default.xml的設定,筆者直接更動hbase-default.xml)
必須更動的參數,否則會有bug:
<property>
<name>hbase.defaults.for.version.skip</name>
<name>hbase.defaults.for.version.skip</name>
<value>true</value>
這個參數必須直接在hbase-default.xml設定
<property> <name>hbase.rootdir</name>
<value>file:///D:/Hbase_rootdir</value>
</property>
另一種安裝順序
1.用SVN抓hbase source code2.去cygwin編譯Hbase 下指令mvn clean install -DskipTests,這時maven會幫我們將需要的jar檔案下載進.m2/repository/org底下。
3.去Eclipse Import Existing Maven Project(Import 方法一樣)
4.若出現跳脫字元的bug,去程式碼多加一個斜線吧
5.設定環境參數(跟上面設定一樣)
一、在eclipse啟動Hbase
1.Run Configuration→新增Java Application→指定Project以及要執行的類別

2. 設定要傳進類別的指令:start

註記:ClassPath、Environment、JRE等項目不必做設定
3. 按下Run
( i ). 如果是第一次在電腦Run可能會出現下圖,關於windows防火牆封鎖的訊息,可以按"取消"沒關係。(紅色的錯誤訊息跟防火牆無關)

(ii). 成功啟動的畫面

成功啟動hbase之後,會在hbase.rootdir指定的目錄下產生hbase資料庫檔案,如此一來相當於在windows上建一個hbase。

成功啟動hbase我們可以在瀏覽器打上localhost:60010,可以看hbase的狀態。顯示Master、RegionServer、Table、Task......等訊息。

二、進入hbase shell
1. Run Configuration→新增Java Application→指定Project與Main class

2. 設定要傳給Main的參數,因為hbase shell是靠JRuby運作,所以這邊Program arguments與VM arguments的參數都是指定JRuby的檔案或函式庫

註記:ClassPath、Environment、JRE等項目不必做設定
3. 按下Run
成功啟動進入hbase shell,可以在畫面上打字下指令。
綠色字體是使用者在上面打hbase shell指令。
如果沒有在hbase-default.xml設定hbase.rootdir的話,啟動hbase shell之後下list指令就會一直跑出紅色字體(unable to open socket to .....)

三、Hbase stop
Hbase必須執行stop
最好不可以用terminate方式(按下紅色方形圖案)停止hbase,否則下次會無法正常啟動hbase
肆、注意事項(筆者碰壁筆記):
一、version的問題
Q:如果出現如下訊息file seems to be for and old version of Hbase (0.97.0-SNAPSHOT),如下圖:
一、version的問題
Q:如果出現如下訊息file seems to be for and old version of Hbase (0.97.0-SNAPSHOT),如下圖:

A:必須去hbase-common\src\main\resources\hbase-default.xml
將hbase.defaults.for.version.skip屬性的value改為true

2.在eclipse啟動hbase出現如下錯誤訊息
Q:
Will not attempt to authenticate using SASL
Unable to open socket to 0:0:0:0:0:0:0:1/0:0:0:0:0:0:0:1:2181
錯誤訊息(1):
INFO zookeeper.ClientCnxn: Opening socket connection to server 0:0:0:0:0:0:0:1/0:0:0:0:0:0:0:1:2181. Will not attempt to authenticate using SASL (無法定位登入配置)
ERROR zookeeper.ClientCnxnSocketNIO: Unable to open socket to 0:0:0:0:0:0:0:1/0:0:0:0:0:0:0:1:2181
WARN zookeeper.ClientCnxn: Session 0x141085eb0250001 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.SocketException: Address family not supported by protocol family: connect
at sun.nio.ch.Net.connect(Native Method)
at sun.nio.ch.SocketChannelImpl.connect(SocketChannelImpl.java:532)
at org.apache.zookeeper.ClientCnxnSocketNIO.registerAndConnect(ClientCnxnSocketNIO.java:266)
at org.apache.zookeeper.ClientCnxnSocketNIO.connect(ClientCnxnSocketNIO.java:276)
at org.apache.zookeeper.ClientCnxn$SendThread.startConnect(ClientCnxn.java:958)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:993)
regionserver.HRegionServer$PeriodicMemstoreFlusher: RS:0;YYP-PC:52645.periodicFlusher exiting
INFO regionserver.Leases: RS:0;YYP-PC:52645.leaseChecker closing leases
INFO regionserver.Leases: RS:0;YYP-PC:52645.leaseChecker closed leases
錯誤訊息(2):
INFO regionserver.HRegionServer$PeriodicMemstoreFlusher: RS:0;YYP-PC:52645.periodicFlusher exiting
INFO regionserver.Leases: RS:0;YYP-PC:52645.leaseChecker closing leases
INFO regionserver.Leases: RS:0;YYP-PC:52645.leaseChecker closed leases
INFO zookeeper.ClientCnxn: Opening socket connection to server 127.0.0.1/127.0.0.1:2181. Will not attempt to authenticate using SASL (無法定位登入配置)
WARN zookeeper.ClientCnxn: Session 0x141085eb0250001 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:599)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:350)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1068)

錯誤訊息(3):
java.io.IOException: Target file:/C:/Users/YYP/AppData/Local/Temp/hbase-YYP/hbase/data/hbase/namespace/namespace is a directory
at org.apache.hadoop.fs.FileUtil.checkDest(FileUtil.java:359)
at org.apache.hadoop.fs.FileUtil.checkDest(FileUtil.java:361)
at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:211)
at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:163)
at org.apache.hadoop.fs.RawLocalFileSystem.rename(RawLocalFileSystem.java:292)
at org.apache.hadoop.fs.ChecksumFileSystem.rename(ChecksumFileSystem.java:425)
at org.apache.hadoop.hbase.master.handler.CreateTableHandler.handleCreateTable(CreateTableHandler.java:216)
at org.apache.hadoop.hbase.master.handler.CreateTableHandler.process(CreateTableHandler.java:155)
at org.apache.hadoop.hbase.executor.EventHandler.run(EventHandler.java:131)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:895)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:918)
at java.lang.Thread.run(Thread.java:662)

A:
在hbase-default.xml更改hbase.rootdir屬性
改成絕對路徑(相對路徑還沒測過)
file:///D:/HbaseZ_rootdir
再重新啟動hbase
在hbase-default.xml更改hbase.rootdir屬性
改成絕對路徑(相對路徑還沒測過)
file:///D:/HbaseZ_rootdir
再重新啟動hbase

註記一:
a.
這問題若沒解決雖然可以進入hbase shell
但是下list指令之後會一直出現
"unable to open socket to 0:0:0:0:0:0:0:1/0:0:0:0:0:0:0:1:2181"訊息
b.曾經根據網路解決方案,試過修改system32/drivers/etc/hosts的IP與主機對應名稱,但此方法對我這案例無效,問題依然存在。
c.如果原始碼已經用maven build過後,電腦主機名稱最好別隨意更改。
如果執意要改電腦名稱,那就改名之後,再用maven build一次,筆者沒試過,不保證會成功。
d.這bug跟似乎防火牆無關,筆者在自家裡試過也出現同樣問題。
註記二:
筆者為了解決bug,曾經更動的地方
1. system32/drivers/etc/hosts
網路上有說如果遇到unable to open socket to 0.0:0.0.0的bug,可以更改hosts的內容。但是筆者依照網路上所說更動,問題依然存在。最後是設定hbase.rootdir給定絕對路徑問題就解決了,如果用本文方法無法解決那就用網路上的方法更動hosts吧。
2.zookeeper.quorum,依照預設值localhost。
("hbase.zookeeper.quorum must read 127.0.0.1 because for some reason localhost does not seem to resolve properly on Cygwin"但本案例並非在Cygwin跑hbase所以就不更動啦。依照預設值localhost)
3.regionservers設定檔,維持localhost
A.貼上可以成功啟動並執行hbase shell時候的ClassPath配置

B.貼上可以正常執行hbase-server的maven jar檔案配置

{kind=link}


Zookeeper設定
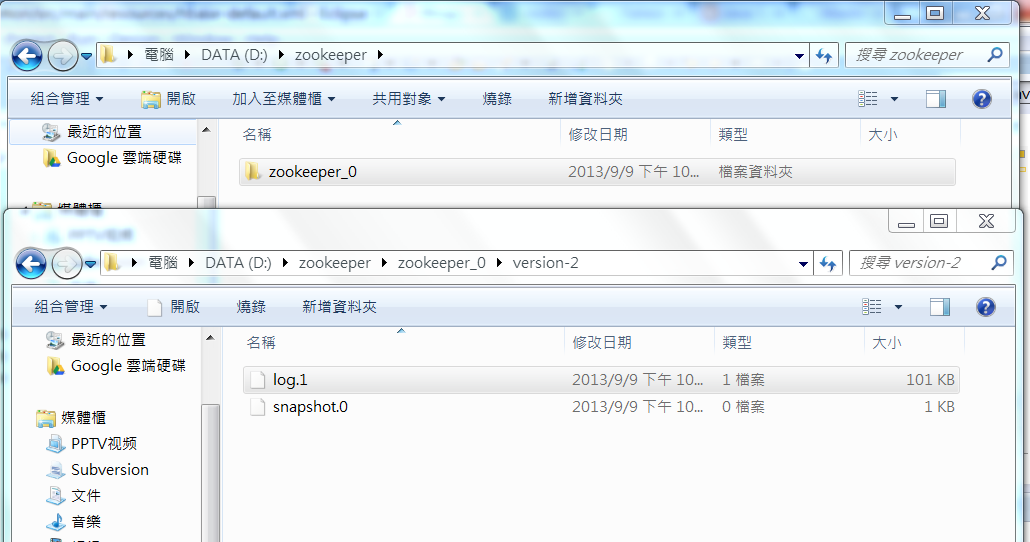
我們可以設定zookeeper的檔案存放目錄。
在hbase-default.xml設置
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>D:/zookeeper</value>
</property>
這邊路徑不可以寫成file:///D:/zookeeper
參考網站
http://www.cnblogs.com/shitouer/archive/2012/10/24/2736923.html
http://michaelmorello.blogspot.tw/2012/06/hbase-096-eclipse-maven.html
2013年8月23日 星期五
Format hadoop出現錯誤cannot remove current directory
cannot remove current directory
因為我將haoop放在根目錄之下
可能是沒有權限刪除檔案的關係
手動刪除之後再格式化就得了
因為我將haoop放在根目錄之下
可能是沒有權限刪除檔案的關係
手動刪除之後再格式化就得了
2013年7月17日 星期三
安裝HBase
版本問題:
"據說"跟hadoop1.1.2匹配的是hbase0.95.0,hadoop1.0.?與hbase0.94.7匹配
一切依照下載後的hbase lib目錄下的hadoop-core-x.x.x.jar版本編號
依照過去安裝NS2+MOVE+SUMO經驗
最好還是別總是用最新版本的系統
否則會有不相容的問題
1.下載hbase-0.96.cdh4.3.0版本(配合hadoop 2.0.0 cdh 4.30)
2.解壓縮
3.設定hbase.site.xml
4.(依照白皮書所做)
修改/etc/security/limits.conf
增加
hadoop(使用者帳號) - nofile 32768
在/etc/pam.d/common-session
最後一行增加
session required pam_limits.so
孜孜科(待續
在Hbase無法啟動並警告說無法找到安裝的java時候
編輯conf/hbase-env.sh檔案,刪除JAVA_HOME這行註解符號
並將此行所指定的Java路徑修改為你所安裝的java路徑
Error:JAVA_HOME is not set and java could not be found
啟動hbase之後查看master node log
INFO org.apache.hadoop.hbase.catalog.CatalogTracker: Failed verification of .META.,,1 at address=.......................................; org.apache.hadoop.hbase.NotServingRegionException:
主要是因為conf/hdfs-site.xml裡面的xceivers至少要4096
我寫1024這樣是不夠的
"據說"跟hadoop1.1.2匹配的是hbase0.95.0,hadoop1.0.?與hbase0.94.7匹配
一切依照下載後的hbase lib目錄下的hadoop-core-x.x.x.jar版本編號
依照過去安裝NS2+MOVE+SUMO經驗
最好還是別總是用最新版本的系統
否則會有不相容的問題
1.下載hbase-0.96.cdh4.3.0版本(配合hadoop 2.0.0 cdh 4.30)
2.解壓縮
3.設定hbase.site.xml
4.(依照白皮書所做)
修改/etc/security/limits.conf
增加
hadoop(使用者帳號) - nofile 32768
在/etc/pam.d/common-session
最後一行增加
session required pam_limits.so
孜孜科(待續
在Hbase無法啟動並警告說無法找到安裝的java時候
編輯conf/hbase-env.sh檔案,刪除JAVA_HOME這行註解符號
並將此行所指定的Java路徑修改為你所安裝的java路徑
Error:JAVA_HOME is not set and java could not be found
啟動hbase之後查看master node log
INFO org.apache.hadoop.hbase.catalog.CatalogTracker: Failed verification of .META.,,1 at address=.......................................; org.apache.hadoop.hbase.NotServingRegionException:
主要是因為conf/hdfs-site.xml裡面的xceivers至少要4096
我寫1024這樣是不夠的
2013年7月2日 星期二
eclipse啟動DHFS
4.从CMD进入到src\contrib\eclipse-plugin目录,执行以下命令:eclipse.home=D:/eclipse/需要指定你eclipse的安装目录version=0.20.2-cdh3u3 是你的hadoop版本 ant -Declipse.home=D:/eclipse/ -Dversion=0.20.2-cdh3u3 jar 会在build\contrib\eclipse-plugin生成jar文件,但这时还不可以用。否则会出现错误: An internal error occurred during: "Map/Reduce location status updater". org/codehaus/jackson/map/JsonMappingException An internal error occurred during: "Connecting to DFS myhadoop". org/apache/hadoop/thirdparty/guava/common/collect/LinkedListMultimap 5.还要从{hadoop根目录}/lib下,找到jackson-core-asl-1.5.2.jar,jackson-mapper-asl-1.5.2.jar,guava-r09-jarjar.jar把他们都解压出来放入刚生成的hadoop-eclipse-plugin-0.20.2-cdh3u3.jar classes目录下(可以通过winrar直接拖进去) 6.最后,把hadoop-eclipse-plugin-0.20.2-cdh3u3.jar放进eclipse的dropin目录,重启eclipse就可以了。 PS:本来想把这些包拷贝进lib目录下,然后改MANIFEST.MF,发现打死不可以。。不知道为什么 Filed under: Hadoop, Java Tagged: CDH3u3, eclipse
hadoop eclipse plugin 1.1.2
據說舊版的(0.x.x)hadoop有附送eclise-plugin.jar
不過從1.X.X板之後就沒了
每個eclipse不一定跟hadoop相容
所以開發者就自己必須更改相關參數自建jar啦
hadoop(1.1.2)的eclipse-plugin放在hadoop家目錄下的src/contrib/路徑中
如果直接將eclipse-plugin資料夾複製到eclipse的plugin之下
eclipse仍然不能使用hadoop外掛套件
首先確認ubuntu已經安裝ant
本人很懶
所以直接用
sudo apt-get install ant
安裝ant
設定過程請參閱
中國blog
之後
進入haoop/src/contrib/eclipse-plugin目錄打上ant
最後在hadoop/build/contib/eclipse-plugin目錄生會看到打包好的hadoop-eclipse-plugin-1.1.2.jar
將這個檔案丟到eclipse的plugins資料夾裡即可
打開eclipse之後,卻出現Unsupported major.minor version 51.0錯誤
點開log訊息意思是說
有些jar是用jdk1.6.0_27編譯而成
有些是用jdk1.7.25編譯而成
查看eclipse-plugin-1.1.2.jar包裡面所有的MANIFEST.MF文件
裡面有些jar採用jdk1.5 jdk1.4編譯而成
沒道理jdk1.5 jdk1.4沒有出現錯誤訊息
而jdk1.6卻給我出現錯誤訊息
所以我猜應該不是eclipse採用的jdk版本與ubuntu系統採用jdk版本不一樣
後來發現
用root帳號打上java -version
root採用的是ubuntu內建的openjdk(版本是1.6.0_27)
版本號碼跟eclipse出現的error log完全一樣
所以我猜應該是
在利用ant打包時候某個時段採用了以root身分採用內建的1.6.0_27打包jar
root跟使用者帳號採用的jdk版本不一樣,編譯出來的jar不被eclipse接納
解決方法:
用root帳號在terminal打上update-alternatives --config java
出現以下畫面

選擇自己安裝的jdk
最後再次使用ant打包eclipse-plugin
(以hadoop帳號執行)
終於,
千呼萬喚始出來......................

不過從1.X.X板之後就沒了
每個eclipse不一定跟hadoop相容
所以開發者就自己必須更改相關參數自建jar啦
hadoop(1.1.2)的eclipse-plugin放在hadoop家目錄下的src/contrib/路徑中
如果直接將eclipse-plugin資料夾複製到eclipse的plugin之下
eclipse仍然不能使用hadoop外掛套件
首先確認ubuntu已經安裝ant
本人很懶
所以直接用
sudo apt-get install ant
安裝ant
設定過程請參閱
中國blog
之後
進入haoop/src/contrib/eclipse-plugin目錄打上ant
最後在hadoop/build/contib/eclipse-plugin目錄生會看到打包好的hadoop-eclipse-plugin-1.1.2.jar
將這個檔案丟到eclipse的plugins資料夾裡即可
打開eclipse之後,卻出現Unsupported major.minor version 51.0錯誤
點開log訊息意思是說
有些jar是用jdk1.6.0_27編譯而成
有些是用jdk1.7.25編譯而成
查看eclipse-plugin-1.1.2.jar包裡面所有的MANIFEST.MF文件
裡面有些jar採用jdk1.5 jdk1.4編譯而成
沒道理jdk1.5 jdk1.4沒有出現錯誤訊息
而jdk1.6卻給我出現錯誤訊息
所以我猜應該不是eclipse採用的jdk版本與ubuntu系統採用jdk版本不一樣
後來發現
用root帳號打上java -version
root採用的是ubuntu內建的openjdk(版本是1.6.0_27)
版本號碼跟eclipse出現的error log完全一樣
所以我猜應該是
在利用ant打包時候某個時段採用了以root身分採用內建的1.6.0_27打包jar
root跟使用者帳號採用的jdk版本不一樣,編譯出來的jar不被eclipse接納
解決方法:
用root帳號在terminal打上update-alternatives --config java
出現以下畫面
選擇自己安裝的jdk
最後再次使用ant打包eclipse-plugin
(以hadoop帳號執行)
終於,
千呼萬喚始出來......................
訂閱:
文章 (Atom)